Emerging Tech Stack for Agentic AI
Our industry feels like it’s at an inflection point. For the last couple of years, much of the excitement around Large Language Models has been centered on the remarkable capability of a single model responding to a single prompt. This is a powerful paradigm, but it is, I feel, just the beginning. The more profound shift is toward what we might call Agentic AI—systems that don’t just respond, but can (arguably) “reason”, plan, and take action to accomplish a goal.
A frequent pattern I’ve observed is that as teams move from building simple demos to production agentic systems, they rediscover a familiar truth. Just as modern web applications are typically built with a coherent stack of technologies, so too is Agentic AI. The notion of a “Full Stack” is re-emerging, optimized for the unique challenges of building intelligent, autonomous systems.
This article, then, is my attempt to sketch out the layers of this emerging stack. The specific tools I mention are illustrative and will inevitably change, but my feeling is that the architectural layers themselves represent a durable pattern for building these complex systems.
The Data Foundation: Preparing the Agent’s Knowledge
An agent’s ability to perform useful work is fundamentally limited by its access to high-quality, relevant information. While LLMs have a vast general knowledge, their real value in an enterprise context comes from grounding their reasoning in specific, private data. This leads to the first part of our stack: a data pipeline dedicated to transforming raw information into a format the agent can use.
This process typically involves three distinct steps:
-
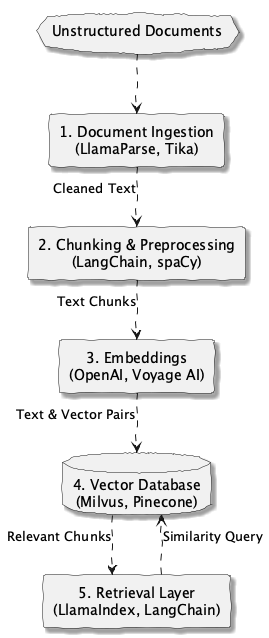
Document ingestion: The first challenge is simply getting unstructured data out of its container. This means parsing complex documents like PDFs, Word files, or HTML pages to extract clean text and metadata. Tools like LlamaParse or the venerable Apache Tika are designed for this very purpose, acting as the entry point to our pipeline.
-
Chunking & preprocessing: Once we have the text, we can’t feed a 200-page document to a model. We must break it down into smaller, semantically coherent “chunks.” This is a surprisingly nuanced task. A simple fixed-size split can break a sentence in half, destroying its meaning. More sophisticated approaches use NLP libraries like spaCy or tools within frameworks like LangChain to split text along sentence or paragraph boundaries.
-
Embeddings: This is the most crucial transformation. We take our text chunks and convert them into vector embeddings—numerical representations that capture the semantic meaning of the text. An embedding model, such as those from OpenAI or Voyage AI, maps concepts that are close in meaning to points that are close in vector space. This is what enables the agent to find relevant information without relying on simple keyword matching.
The Knowledge Core: The Agent’s Memory
With our data transformed into a collection of vectors, we need a place to store them and a way to retrieve them efficiently. This forms the agent’s long-term memory.
-
Vector database: A traditional database is indexed to find exact matches. A vector database, however, is designed for a different kind of query: “Find me the chunks of text that are most semantically similar to this new query.” It’s an engine for similarity search. Systems like Milvus, Pinecone, or even a library like FAISS serve this purpose, acting as the persistent knowledge store for the agent.
-
Retrieval component: The logic of querying the vector database and preparing the retrieved information for the LLM is handled by a retrieval layer. This is the core of what is often called Retrieval-Augmented Generation (RAG). A good retrieval layer, often managed by a framework like LlamaIndex or LangChain, might fetch several relevant chunks, re-rank them for relevance, and format them neatly to be injected into the LLM’s prompt.
This flow, from raw document to retrieved context, forms the backbone of an agent’s ability to answer questions based on private data. We can visualize this data pipeline as follows.
The Reasoning and Action Layer
Once the agent has retrieved the necessary context, the core reasoning process can begin. This is where the LLM itself comes into play, orchestrated by a layer that manages the interaction.
-
Prompt engineering & orchestration: This is far more than just formatting a string. This layer is responsible for taking the user’s original query, weaving in the retrieved context, and providing clear instructions to the LLM on how to behave. While simple orchestration can be done with LangChain, more advanced, programmatic approaches like DSPy are emerging. These treat prompt engineering less like a black art and more like a modular program, which I feel is a promising direction.
-
LLMs (The reasoning engine): This is the “CPU” of our stack, the component that performs the actual reasoning. Whether it’s Gemini, Llama, or a model from OpenAI or Anthropic, this is where the retrieved context and the user’s query are synthesized into a coherent answer or a plan of action.
-
Frontend: This is the user interface of the agent. It might be a simple chat window built quickly with Gradio or Streamlit for internal use, or a sophisticated interface built with React or Next.js for a customer-facing product.
Cross-Cutting Concerns
As with any mature software stack, there are foundational, cross-cutting concerns that support the entire system. In my experience, teams that ignore these until the end often struggle to move from a prototype to a production system.
-
Observability & evaluation: How do we know if our agent is performing well? When it gives a wrong answer, how do we debug the cause? Was it a bad retrieval? A poorly formulated prompt? Or did the LLM hallucinate? This is where observability tools like LangSmith and Arize are critical. They provide the tracing and evaluation necessary to diagnose and improve the system.
-
Infrastructure & deployment: Agentic systems are complex applications that must be packaged, deployed, and scaled reliably. The discipline of DevOps is just as relevant here. We use tools like Docker to containerize our components and Kubernetes to manage them, all running on a foundational cloud platform like AWS, Azure, Google Cloud, and so on
This brings us to a more complete picture of the full stack. The frontend that the user sees is merely the tip of the iceberg; the real engineering complexity lies in the integrated layers below.
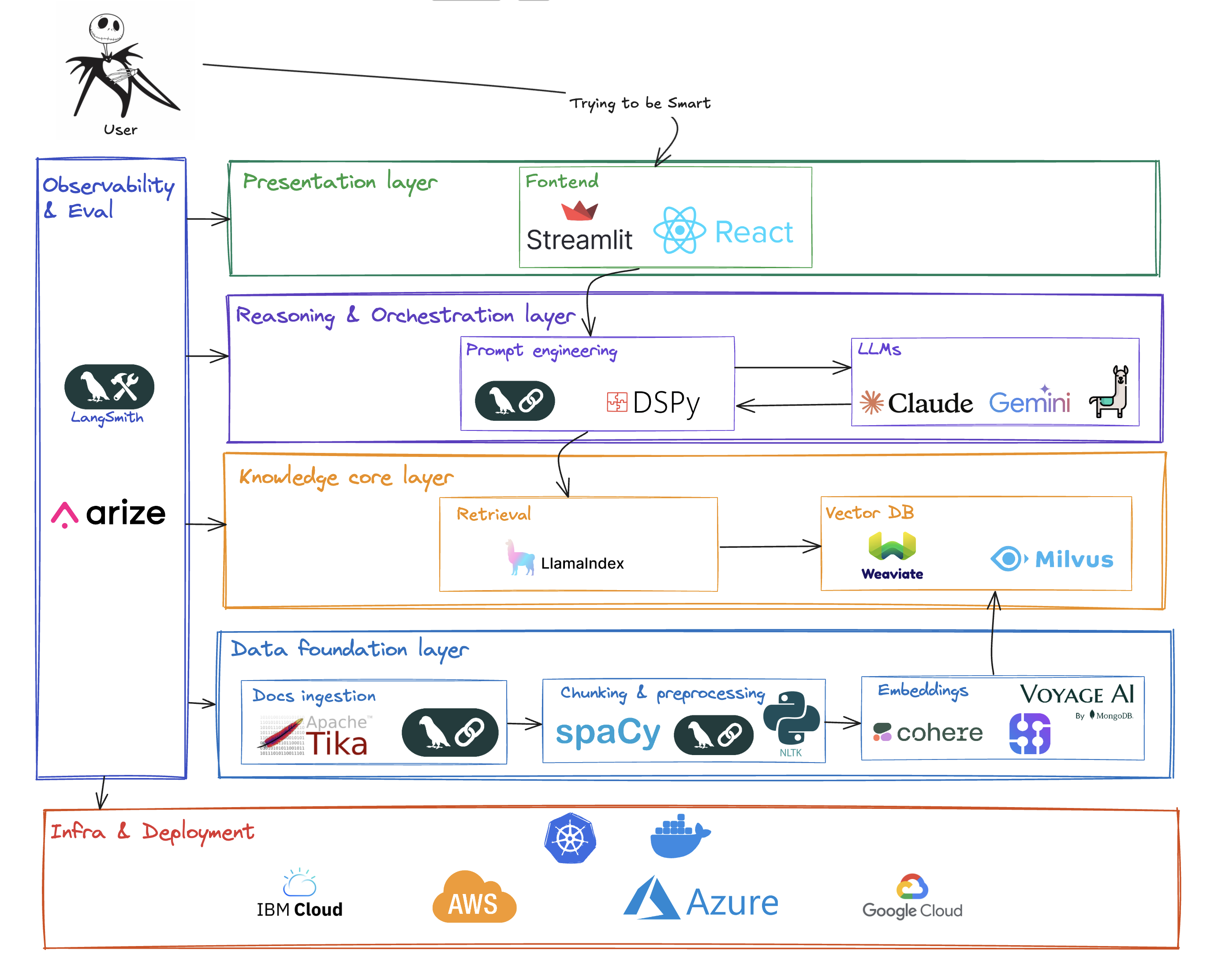
The key takeaway is that building robust Agentic AI is a full-stack discipline, a fun architectural endeavor. What’s exciting to me is that we are seeing the patterns solidify. While the specific vendors and libraries will surely evolve, the conceptual layers, from data ingestion and retrieval to reasoning and observability, provide a durable mental model for engineering these systems.
The iceberg is a fitting analogy. The conversational interface is what everyone sees, but the real work, the deep engineering that provides the stability and intelligence, lies in the vast, integrated stack beneath the surface.
And life goes on …